mC2
System Architecture
mC2 is a fully verified concurrent OS kernel that can also double as a hypervisor.
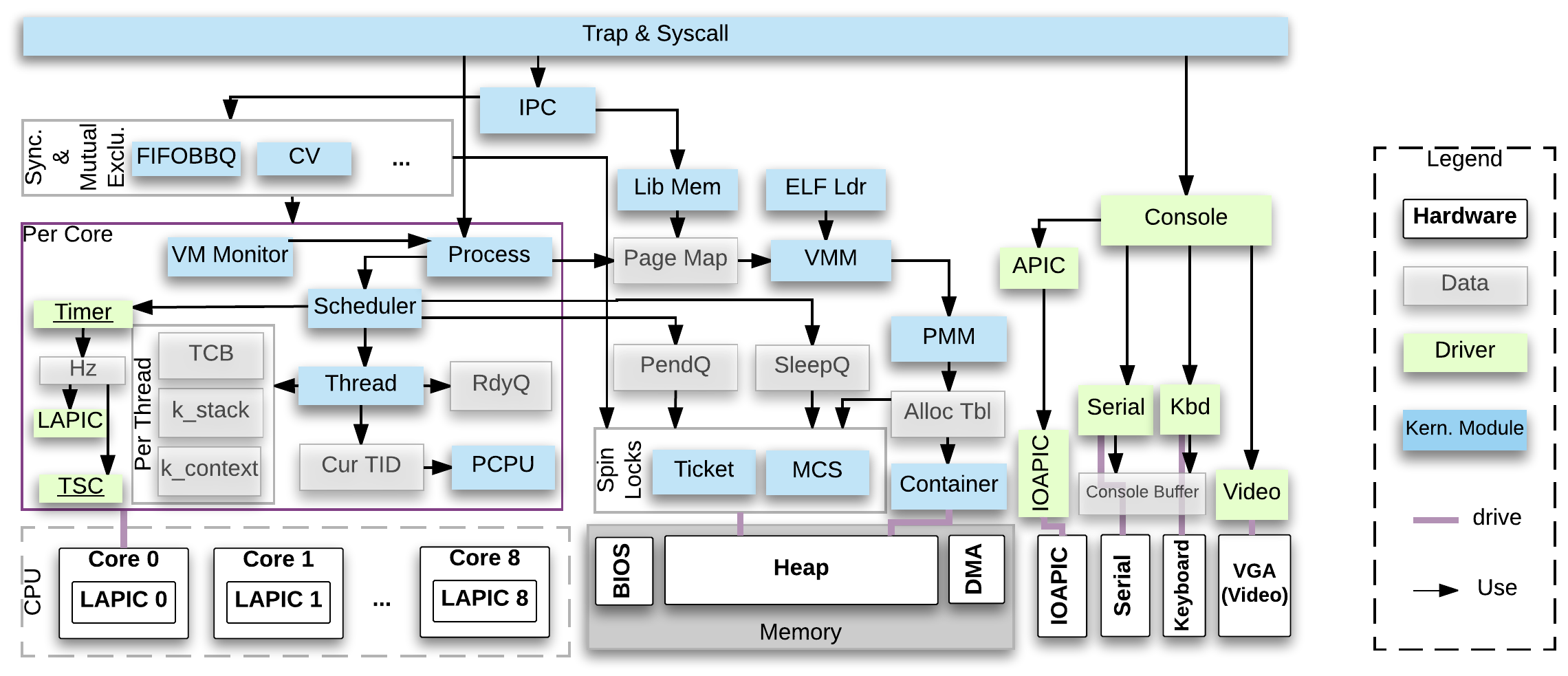
- mC2 runs on an Unmanned Ground Vehicle (UGV) with a multicore Intel Core i7 machine.
- mC2 consists of 6100 lines of C and 400 lines of x86 assembly.
- mC2 can boot three Ubuntu Linux system as guests (one each on the first three cores).
- The kernel also contains a few simple device drivers.
mC2 is an extensible kernel, which already re-use many parts of implementations and proofs of mCertiKOS.
- We take the certified sequential mCertiKOS kernel, and extend the kernel with various features.
- Some features were initially added in the sequential setting but later ported to the concurrent setting.
Module Hierarchy
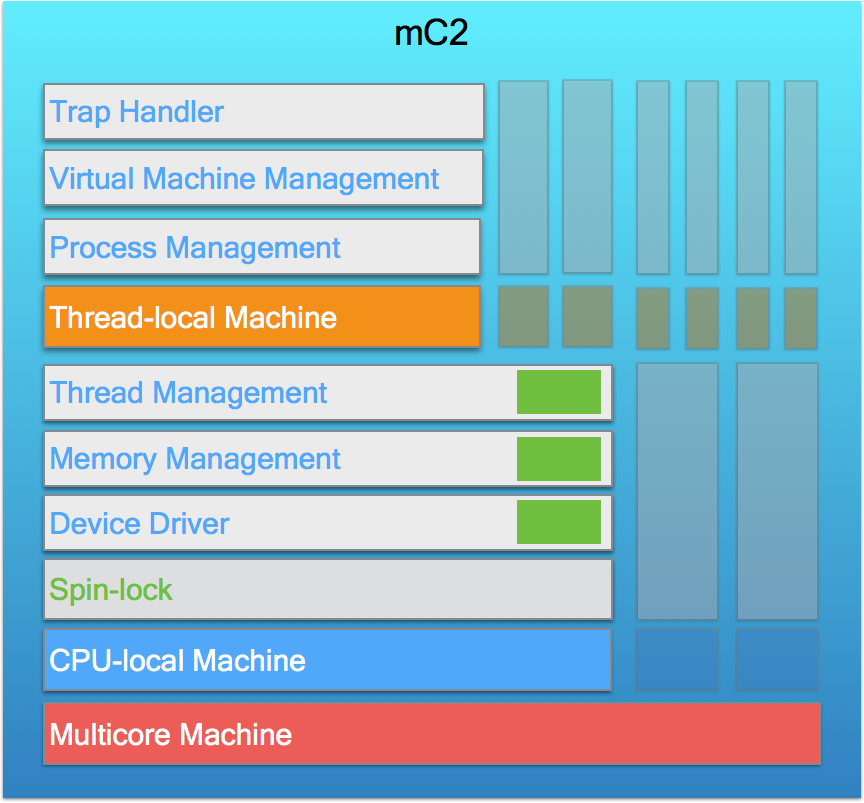
Multicore Machine
The pre-initialization module in the bottom layer, which allows arbitrary interleavings at the level of assembly instructions.
CPU-local Machine
The module which is lifted from the bottom machine using machine refinement and instantiated with a particular active CPU.
Spin-lock Module
The mC2 kernel provides two kinds of spinlocks: ticket lock and MCS lock. They have the same interface and thus are interchangeable.
Device Driver Module
The mC2 kernel handles a few simple device drivers (e.g. interrupt controllers and serial devices).
Memory Management Module
This module can be divided as three parts; physical memory management, virtual memory management, and shared memory management.
- Physical memory management
- Introduces the page allocation table and the page allocator, which are shared among different CPUs.
- Dynamically tracks and bounds the memory usage of each thread (A container object is used to record information for each thread).
- Virtual memory management
- Provides consecutive virtual address spaces on top of physical memory management.
- Shared memory management
- Provides a protocol to share physical pages among different user processes.
Thread Management Module
This module introduces the shared queue library, the thread control block, and the thread scheduler as well as manages the resource of dynamically spawned threads and their meta-data.
- Shared queue library
- Abstracts the queues implemented as doubly-linked lists into abstract queue states (i.e, Coq lists).
- Provides the atomic interfaces for shared queue operations by associating each shared queue with a lock.
- Thread scheduler
- Done by three primitives: yield, sleep, and wakeup.
- Implemented using the shared queue library.
Thread-local Machine
Per-thread machine model after introducing and by using the thread scheduler (software scheduler). This machine lifting form per-CPU to per-thread is similar to the machine lifting from multicore to per-CPU.
Process Management Module
This module introduces the starvation free condition variable as well as synchronized inter process communication (IPC).
Virtual Machine Management Module
This module is for supporting Intel hardware virtualization.
Trap Handler Module
This module contains the top layer that provides system call interfaces and serves as a specification of the whole kernel.
Performance
Hypervisor Performance
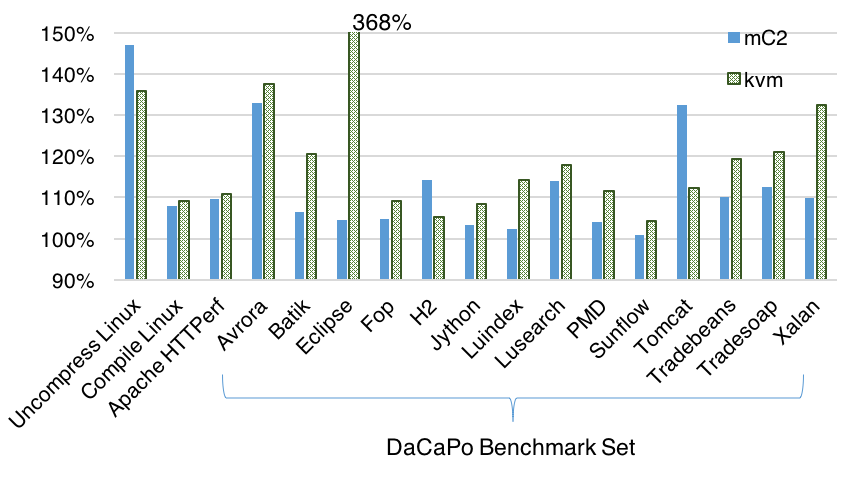
The performance of some macro benchmarks on Ubuntu 12.04.2 LTS running as a guest.
- The benchmarks are on Linux as guest in both KVM and mC2, as well as on the bare metal.
- The guest Ubuntu is installed on an internal SSD drive.
- KVM and mC2 are installed on a USB stick.
- We use the standard 4KB pages in every setting — huge pages are not used.
The figure contains a compilation of standard macro benchmarks: unpacking of the Linux 4.0-rc4 kernel, compilation of the Linux 4.0-rc4 kernel, Apache HTTPerf (running on loopback), and DaCaPo Benchmark 9.12. We normalize the running times of the benchmarks using the bare metal performance as a baseline (100%).
Concurrency Overhead
Ticket Lock vs. MCS Lock in mC2
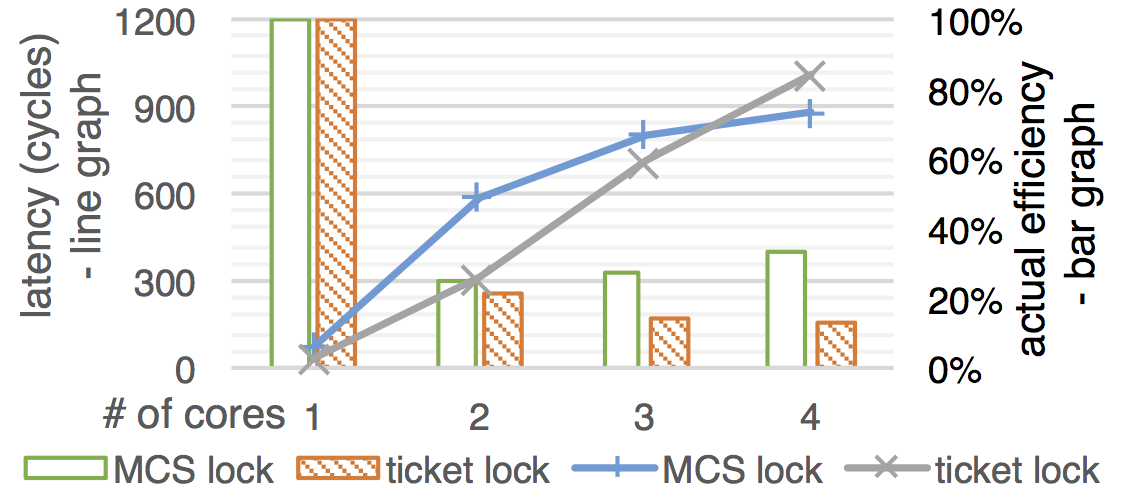
Performance comparison between ticket lock and MCS lock implementations in mC2
- We put an empty critical section (payload) under the protection of a single lock.
- The latency is measured by taking a sample of 10,000 consecutive lock acquires and releases (transactions) on each round.
- It is expected that the slowdown should be proportional to the number of cores, because all transactions in this benchmark are protected by the same lock.
- In the single core, ticket locks impose 34 cycles of overhead, while MCS locks impose 74 cycles (line chart).
- We normalize the latency against the baseline (single core) multiplied by the number of cores in order to show the actual efficiency of the lock implementations (bar chart).
Big-kernel Lock vs. Fine-grained Lock
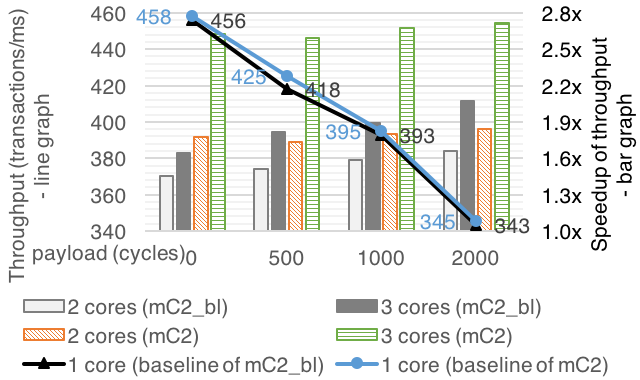
Comparison between the kernel with big-kernel-lock and fine-grained lock (Speedup of throughput of mC2 vs. mC2-bl in a client/server benchmark under various server payloads (0-2,000)).
- A pair of server/client processes on each core to measure the total throughput (i.e., the number of transactions that servers make in each millisecond) across all available cores.
- A server’s transaction consists of first performing an IPC receive from a channel i, then executing a payload, and finally sending a message to channel i + 1.
- A client executes a constant payload of 500 cycles, sends an IPC message to channel i, and then receives its server’s message through channel i + 1.
- The speedup is normalized against its own baseline (single core throughput) for each kernel version separately.
Our measurement cannot achieve perfect scaling as the number of cores increases because;
- Each core must execute some system processes which run at constant rates and consume CPU resources.
- We did not align kernel data structures against cache-line size.
Acknowledgements
This project is sponsored by NSF grants 1065451, 1521523, and 1319671, DARPA HACMS grant FA8750-12-2-0293, and other DARPA grants FA8750-10-2-0254, FA8750-16-2-0274, and FA8750-15-C-0082. Any opinions, findings, and conclusions contained in this document are those of the authors and do not reflect the views of these agencies.